by Kavon Benbow

This is project where I will be using certain variables in the “2023-2024 NBA Player Stats” Dataset off of kaggle to determine who were the top players of that specific NBA season.
Introduction
The NBA (National Basketball Association) has been giving their players accolades and awards for completing certain requirements or being the best at something. One of those awards is being selected to an All NBA Team at the end of season which takes the best player from each position category and puts them on a team. This project aims to figure out exactly that who were the most deserving players from the 2023-2024 NBA season that should have been selected for the All NBA Team.

Key Question
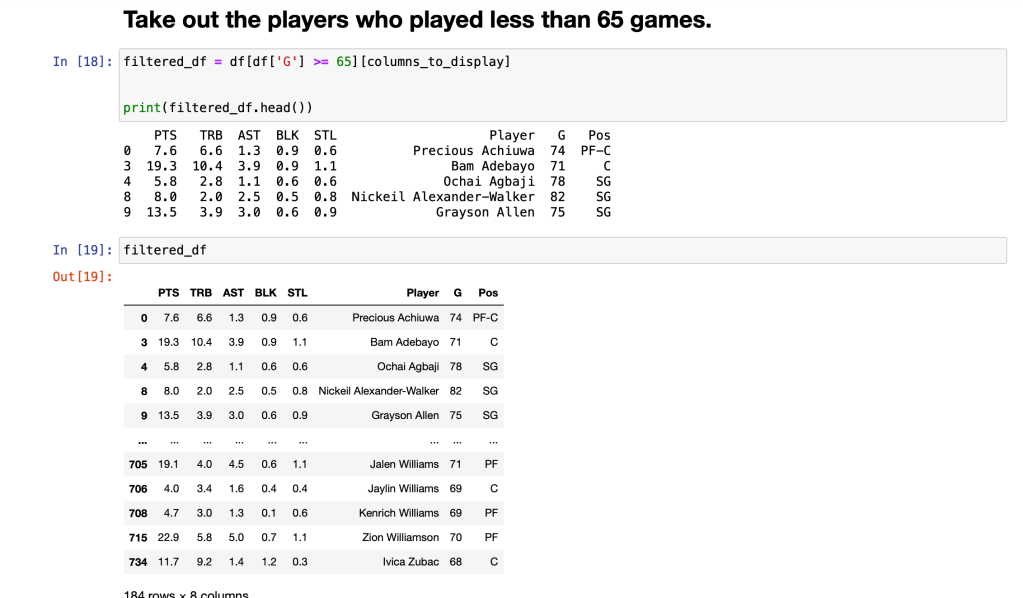
The key question in this is what does take to actually make the All NBA Team. There is only one mandatory requirement in making the team and that is you have had to have played 65 games or more of that specific season to be eligible to make the team.
Introducing The Data
The dataset that I will be using is the “2023-2024 NBA Player Stats” dataset from kaggle for this project. In this dataset they have multiple of variables concerning the NBA but for this project I will only be using the variables for player name, position, points, rebounds, assists, blocks, and steals.
https://www.kaggle.com/datasets/vivovinco/2023-2024-nba-player-stats/data
Pre-Processing The Data
For the data pre-processing I first started out printing the entire dataset which ended being to big because of all the variables included. I then cut it down the specific variables I mentioned earlier. I also had to cut out any players in the dataset who played less than 65 games that season because if they do meet that requirement they cannot be a top player for that season.
Model Selection
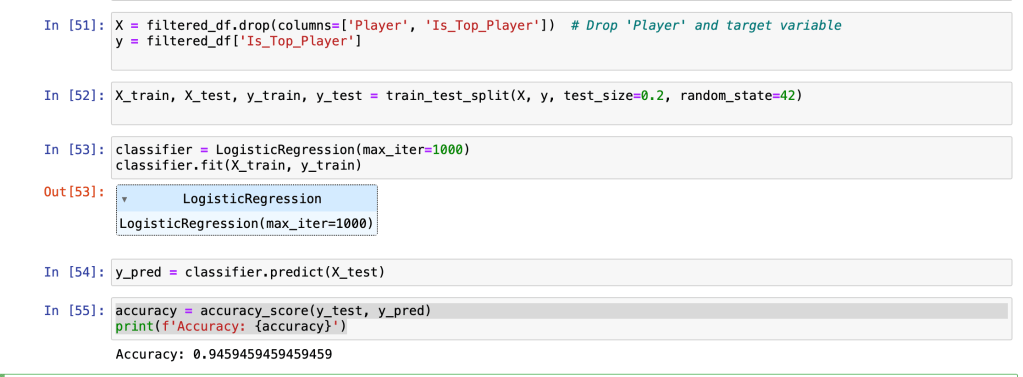
For this project I’ve decided to use a logistic regression model in order to mostly accurately predict whether or not a player is a top player or not. The logistic regression also came with an accuracy score of 94.59%.
Model Training
The model was trained to detect any players who had not played 85 games and omit them from the model. Then it would check the players stats to see if the player excelled in any of the 3 major categories which are points rebounds and assists while also checking steals and blocks etc. If a player meet a certain criteria in a specific stat which is to average more than this certain amount.

Evaluating The Model
The model turned out to do what I wanted to do and main use was to take the player in the top 10-20 that were ranked and see if they qualified to be a top player. I also took all the past all stars from that specific season and see if they deserved to be a top star and said earlier this is with 94.59% accuracy .

Model Tuning
For this model I had to fine tune some specific areas such as game played I also added the ability for the user can type a players name in and be told whether he’s a top player or not. I had to switch the model from only being to say players who have completely all the requirements and not just one because then barely anyone would be considered a top player according to the model.
file:///Users/kavon/Downloads/Project%202%20Data%20Mining%20.html
Predictions and Final Thoughts
For this project before I started I predicted that at least 20 of the 24 top players on the all star would meet the criteria in order to be assumed as a top player as well as an all star because sometimes the two do not correlate. As far as what I predicted I was wrong but I was not by a lot due to the fact that some players were injured during that years all star but still became top players afterward.


Leave a comment